 Overall framework
Overall framework
Abstract
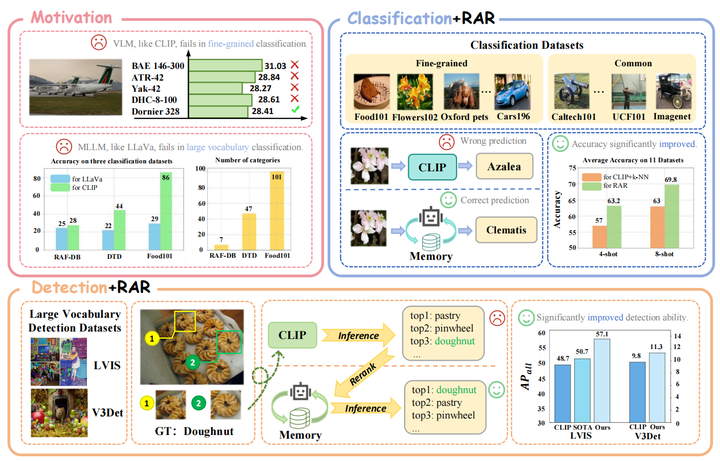
In this paper, we highlight the potential of combining retrieving and ranking with multi-modal large language models to revolutionize perception tasks such as fine-grained recognition, zero-shot image recognition, and few-shot object recognition. Motivated by the limited zero-shot/few-shot of CLIP and MLLMs on fine-grained datasets, our RAR designs the pipeline that uses MLLM to rank the retrieved results. Our proposed approach can be seamlessly integrated into various MLLMs for real-world applications where the variety and volume of categories continuously expand. Our method opens up new avenues for research in augmenting the MLLM’s abilities with the retrieving-augmented solution and could be beneficial for other tasks such as reasoning and generation in future works.
Jiaqi Wang 王佳琦
Research Scientist & Team Leader
Shanghai AI Laboratory
Jiaqi Wang is currently a Research Scientist and Team Leader at Shanghai AI Laboratory, as well as an Adjunct Ph.D. Supervisor at Shanghai Jiao Tong University. His research focuses on visual perception, vision-language models, and the development of benchmarks and datasets in these areas.