Self-supervised Action Representation Learning from Partial Spatio-Temporal Skeleton Sequences
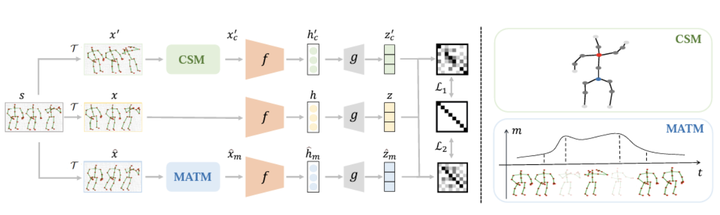 Overall framework
Overall framework
Abstract
Self-supervised learning has demonstrated remarkable capability in representation learning for skeleton-based action recognition. Existing methods mainly focus on applying global data augmentation to generate different views of the skeleton sequence for contrastive learning. However, due to the rich action clues in the skeleton sequences, existing methods may only take a global perspective to learn to discriminate different skeletons without thoroughly leveraging the local relationship between different skeleton joints and video frames, which is essential for real-world applications. In this work, we propose a Partial Spatio-Temporal Learning (PSTL) framework to exploit the local relationship from a partial skeleton sequences built by a unique spatio-temporal masking strategy. Specifically, we construct a negative-sample-free triplet steam structure that is composed of an anchor stream without any masking, a spatial masking stream with Central Spatial Masking (CSM), and a temporal masking stream with Motion Attention Temporal Masking (MATM). The feature cross-correlation matrix is measured between the anchor stream and the other two masking streams, respectively. (1) Central Spatial Masking discards selected joints from the feature calculation process, where the joints with a higher degree of centrality have a higher possibility of being selected. (2) Motion Attention Temporal Maskingleverages the motion of action and remove frames that move faster with a higher possibility. Our method achieves state-of-the-art performance on NTURGB+D 60, NTURGB+D120andPKU-MMDundervariousdownstream tasks. Furthermore, to simulate the real-world scenarios, a practical evaluation is performed where some skeleton joints are lost in downstream tasks. In contrast to previous methods that suffer from large performance drops, our PSTL can still achieve remarkable results under this challenging setting, validating the robustness of our method.
Jiaqi Wang 王佳琦
Research Director
JD Explore Academy
Jiaqi Wang is currently a Research Director at JD Explore Academy, leading the research and development of large language models (LLMs) and vision-language models (VLMs). Previously, he was a Research Scientist at Shanghai AI Laboratory. He also serves as an Adjunct Ph.D. Supervisor at Shanghai Innovation Institute.