BUOL: A Bottom-Up Framework with Occupancy-aware Lifting for Panoptic 3D Scene Reconstruction From A Single Image
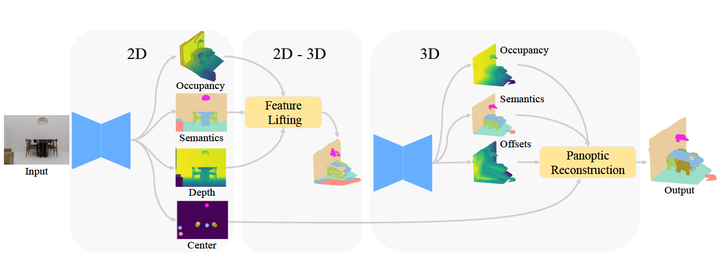 Overall framework
Overall framework
Abstract
Understanding and modeling the 3D scene from a single image is a practical problem. A recent advance proposes a panoptic 3D scene reconstruction task that performs both 3D reconstruction and 3D panoptic segmentation from a single image. Although having made substantial progress, recent works only focus on top-down approaches that fill 2D instances into 3D voxels according to estimated depth, which hinders their performance by two ambiguities. (1) instance-channel ambiguity: The variable ids of instances in each scene lead to ambiguity during filling voxel channels with 2D information, confusing the following 3D refinement. (2) voxel-reconstruction ambiguity: 2D-to-3D lifting with estimated single view depth only propagates 2D information onto the surface of 3D regions, leading to ambiguity during the reconstruction of regions behind the frontal view surface. In this paper, we propose BUOL, a Bottom- Up framework with Occupancy-aware Lifting to address the two issues for panoptic 3D scene reconstruction from a single image. For instance-channel ambiguity, a bottom-up framework lifts 2D information to 3D voxels based on deterministic semantic assignments rather than arbitrary instance id assignments. The 3D voxels are then refined and grouped into 3D instances according to the predicted 2D instance centers. For voxel-reconstruction ambiguity, the estimated multi-plane occupancy is leveraged together with depth to fill the whole regions of things and stuff. Our method shows a tremendous performance advantage over state-of-the-art methods on synthetic dataset 3D-Front and real-world dataset Matterport3D. Code and models will be released.
Jiaqi Wang 王佳琦
Research Scientist & Team Leader
Shanghai AI Laboratory
Jiaqi Wang is currently a Research Scientist and Team Leader at Shanghai AI Laboratory, as well as an Adjunct Ph.D. Supervisor at Shanghai Jiao Tong University. His research focuses on visual perception, vision-language models, and the development of benchmarks and datasets in these areas.